
В Pfam я взяла двудоменную архитектуру, встречающуюся в 48 белковых последовательностях и представленную у бактерий. Она состоит из домена COX15-CtaA и UbiA.
| ID | AC | Название | Число находок в Uniprot |
| PF02628 | COX15-CtaA | Cytochrome oxidase assembly protein | 4464 |
| PF01040 | UbiA | UbiA prenyltransferase | 18222 |
В базе данных Uniprot я искалабактериальные белки, содержащие выбранные домены. Всего находок оказалось 238.
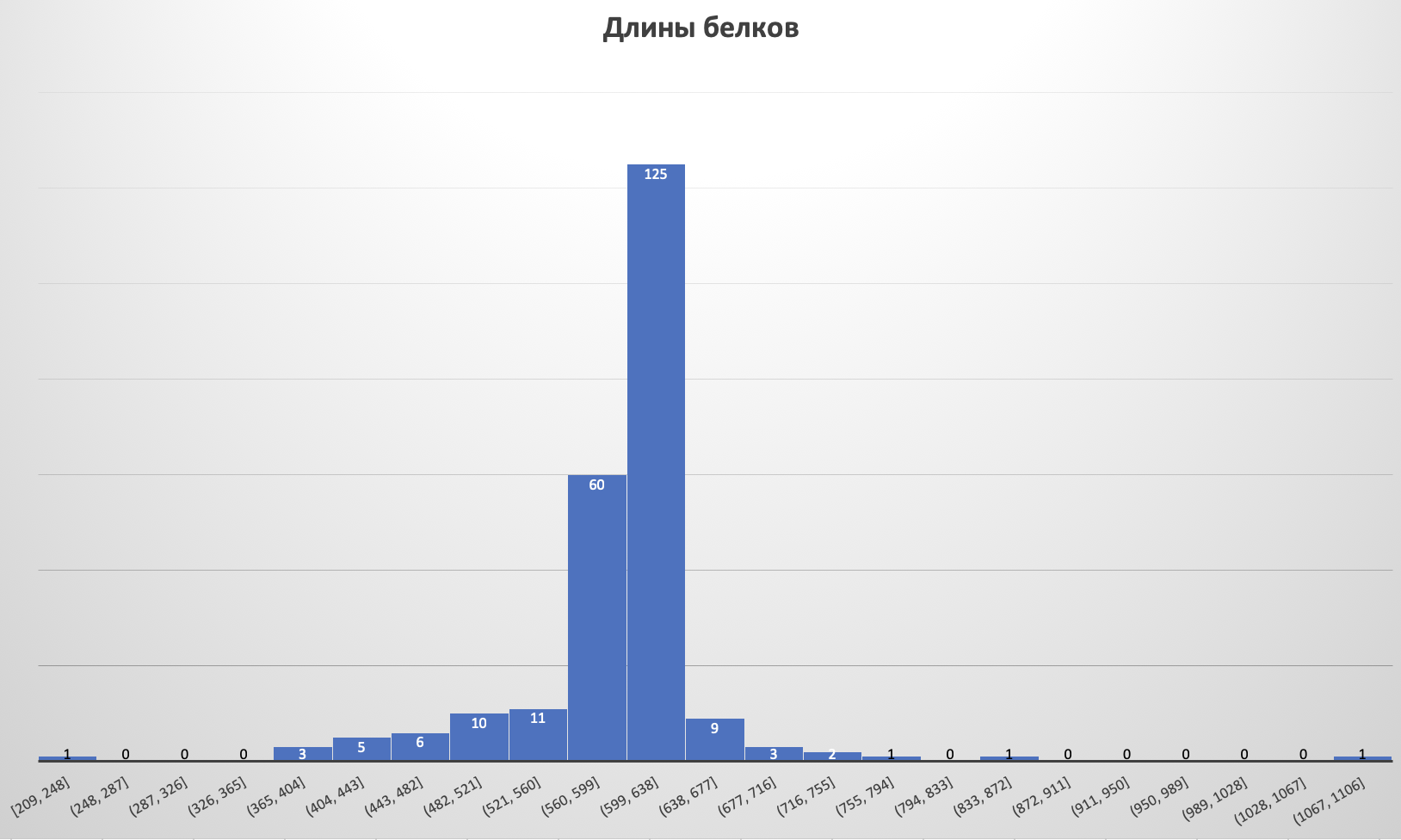
Была построена гистограмма длин белков. Большинство длин лежат в диапазоне [599;638]. Значит эти значения будем считать характерной длиной белка.
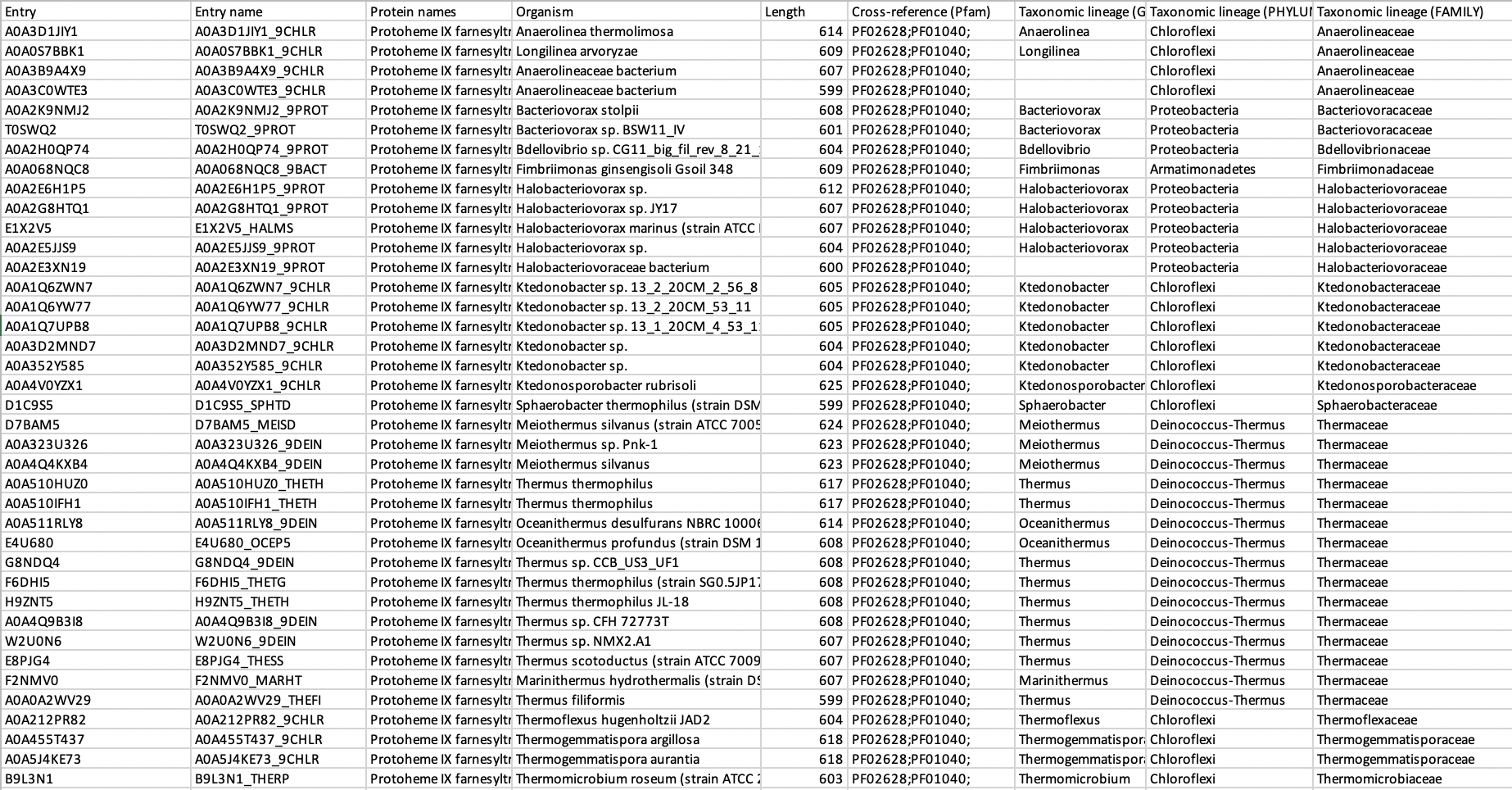
Я выбрала 39 белков различных семейств. Всего в таблице было 12 семейств. Выборку можно увидеть на картинке.
Из Uniprot я взяла последовательности выбранных белков и выровняла с помощью muscle. Команада muscle -in seq_pr9.fasta -out align_seq_pr9.fasta.
До N-концевого блока я удалила 45 нуклеотидов, а для C-концевого удаление не потребовалось. Также я удалила две последовательности, так как они давали длинные вставки.

Для построеня HMM профиля я воспользовалась командой hmm2build -g pr9_build align_pr9.fasta для построения профиля по выравниванию и hmm2calibrate pr9_build для калибровки.
Для проверки профиля я нашла в Uniprot белки, содержащие только первый(pf02628) из двуз доменов. Нашлось 20099 таких белков. Я использовала команду hmm2search --domE 0.1 pr9_build 1_domain.fasta > hmm_res.fasta для поиска белков с двухдоменной архитектурой по профилю выравнивания(порог e-value=0.1).
*Из-за того, что я делала таблицу на маке, при эскпорте в формат xslx некоторые формулы потерялись и остались только цифры. Но, конечно, без формул я не сделала эту таблтицу, так что надеюсь на понимание)*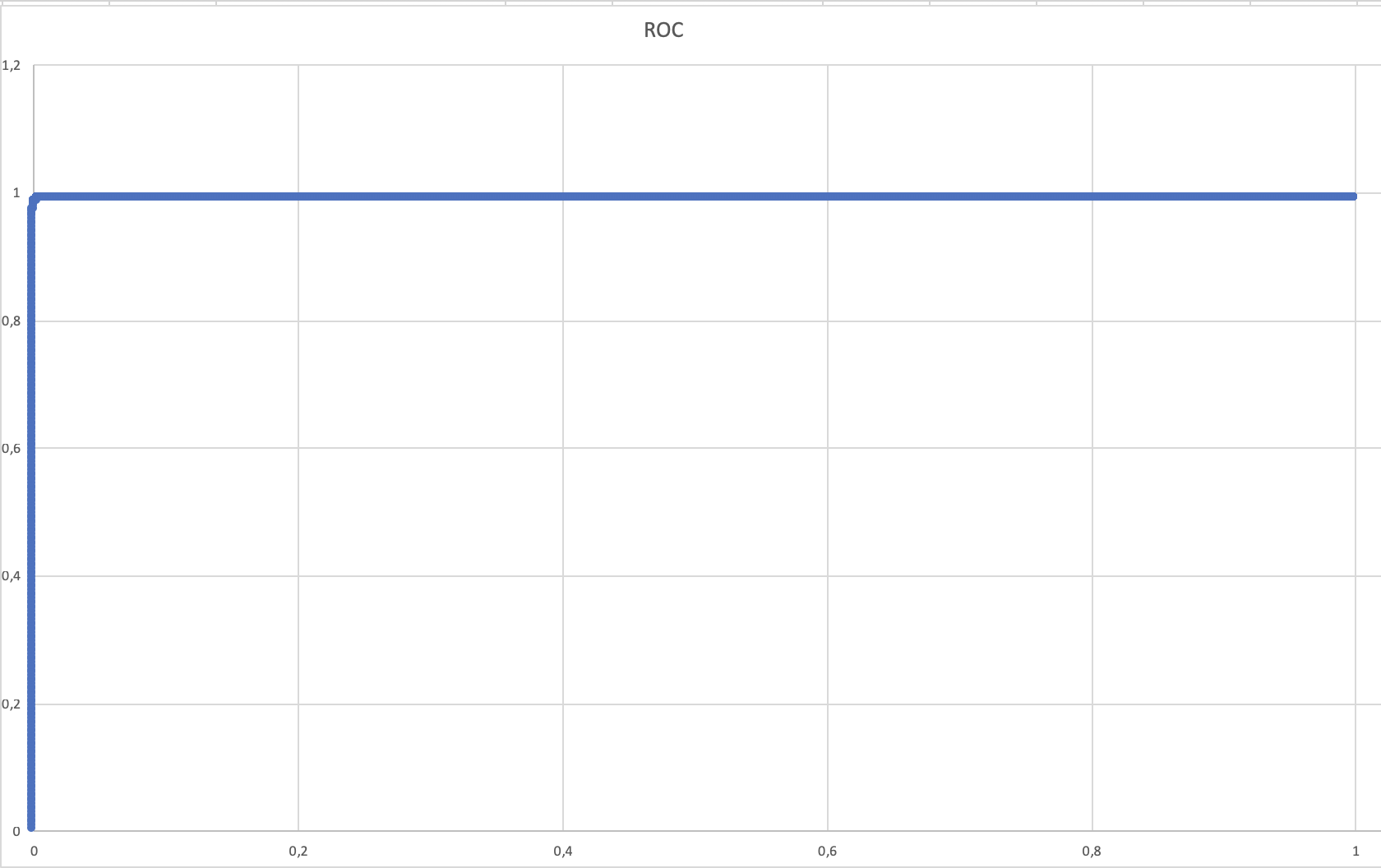
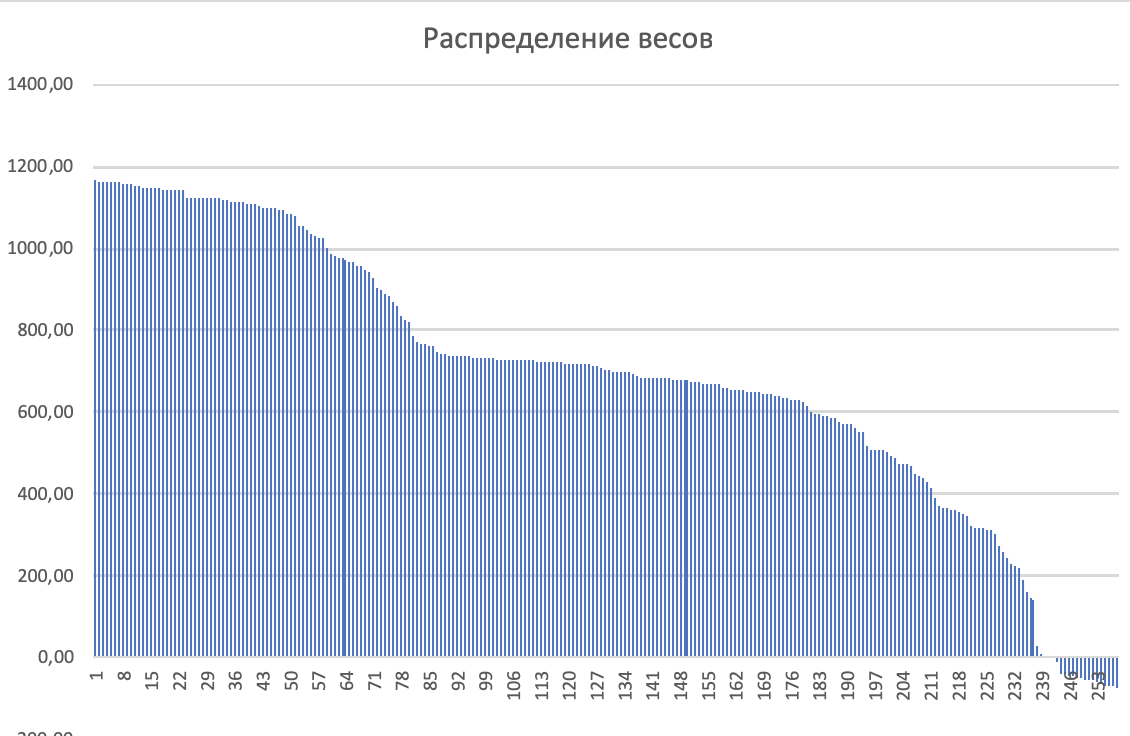
На основе предыдущих данных сделана таблица предсказаний.
